
Your Harness Has a Lifecycle
- Yanbing Li
- Jun 16
- 13 min read

Updated: Jun 26
In one breath: an AI harness is the instructions, memory, tools, and checks wrapped around the model. The standing config you feed it before any task exists (instruction files, memory index, skill listings, permissions) is an engineered artifact you re-pay on every message, and it rots like any artifact left ungoverned. It earns the discipline we already give software: budgets, versioning, drift detection, gated change, archival. Call it Harness Lifecycle Management (HLM). "Lifecycle" is literal, not loose: each piece of harness content is created, deployed into the loaded context, maintained, then demoted to a cheaper tier (or archived) at end of life. The lifecycles even nest: a single rule, a closed work-arc (a bounded piece of work, start to finish), a whole session, each running the same course. (Note: HLM is not ALM or SDLC: those govern the application you're building; HLM governs the harness you build it with.)
The $0.85 empty session
I opened a usage dashboard and one line item made it click: a session that had done almost nothing (a quick question, one answer) cost $0.85. Almost none of it paid for the work. It paid for the setup the harness loads before you even ask your first question: the system's own instructions, its list of tools, its memory catalog, my project notes. That setup is stored once when the session starts, then re-sent (and re-billed) on every message after. And the empty session wasn't an outlier: 41% of my usage ran above 150k tokens, and I'd burned two-thirds of a week's budget in two days.
Most of that load is fixed overhead: the system prompt and tool schemas ship with the harness, and I can't trim them. But one slice was mine to govern, and it had quietly bloated: our project instruction file (a CLAUDE.md, in Claude Code's terms) had grown to 47.4k characters, and the global one added 7.7k more, roughly 12–14k tokens, re-paid on every message. (That four-chars-per-token rule is GPT-era and undercounts Claude, so the real figure, and the savings below, run higher, not lower.)
And you pay on a schedule. The standing prefix (the block of standing tokens at the front of every request, before your task) is stored once when a session first starts, then re-read from cache on every message after.¹ I run three sessions in parallel ("lanes"), so that startup cost lands three times over.
Nobody had ever decided to spend that slice. It had accreted: sprint state from arcs closed months ago, an invoice table, runbooks for a failure that happens twice a year. Every line had been useful once. None had ever been asked to justify staying.
And this wasn't the first time: we'd refactored these files before. But every prior refactor was reactive, triggered by real pain: a token limit hit, a slow boot. Pain-triggered, not guardrail-triggered. The thing built to catch drift had drifted itself.
The artifact you never versioned
Start from one observation: when you work with an AI coding tool, you're not really talking to a model. You're talking to a harness: the structured environment of instructions, memory, tools, and checks wrapped around it. The model is the processor; the harness is the operating system around it. Most of what makes the thing useful, safe, and affordable lives in the harness, not the weights.
So the harness's standing configuration is an engineered artifact. It has a cost model (you pay for it every message), failure modes (it bloats, goes stale, contradicts itself), and accumulating debt. Plenty of artifacts get managed reactively and that's fine: a dotfile, a shell alias, cleaned up when they annoy you. What tips this one over the line is a combination of three things: it's paid continuously, multiplied across every lane, and cost-asymmetric in failure. A handful of saved tokens on one side; a mal-fired rule that costs a client relationship on the other. That combination earns it a standing discipline, not the occasional cleanup. (The first and last of those hold even for a solo, single-session workflow.)
We already have the vocabulary: Application and Product Lifecycle Management, decades of practice for versioning, budgets, drift detection, archival, gated change. The lens transfers concretely: PLM's deprecation policy gives the config a changelog and a path for retiring a stale rule; ALM's promotion gates give its irreversible edits a human gate; even the maintenance split carries over (fix, adapt, improve, harden, plus security patching, which for a harness is the IP-hygiene and permission surface). The frontier (the leading edge of AI tooling) is busy automating the harness's context; what almost nobody does is govern it systematically: treat the always-loaded layer as a costed, versioned artifact, not something to trim when it hurts. That's the missing half HLM names.
A note on what HLM is, and isn’t
The field is already blurring this word. HLM is not the runtime “agent lifecycle” you will see elsewhere: checkpoints, retries, state that survives a crash. Those govern what happens while the agent runs.
HLM governs the layer underneath all of that: the always-loaded configuration. The instructions, tool schemas, and resident memory that get re-loaded and re-billed on every single call. Not the runtime machinery, but the standing configuration that every run inherits.
The rest of this essay is the worked example: how one HLM practice, load-tier demotion, clawed back the governable part of those $0.85 sessions, and the small self-regulating loop that keeps the fix from rotting like every fix before it.
Always-loaded bytes are rent
Harness context isn't one thing. Every piece of standing content sits in a load tier, and the tiers have wildly different cost structures:
Always-loaded. In the instruction file the harness injects into every session, written to the cached prefix at boot and re-read on every message, in every concurrent lane. This is rent, due continuously, forever. It comes in two reaches: a project file, paid in every session of that project, and a global one, paid in every session of every project you touch, the highest-leverage surface you own, which is why its budget is strictest.
On-demand. In a separate file the model pulls in by address: a pointer in the always-loaded tier names it and says when to read it. Retrieval is deliberate and deterministic: you know it's there, you fetch it. Cost: one pointer line, plus a read when (and only when) it's relevant. (Skills and reference files.)
Recalled. In an associative store with no pointer: an entry surfaces when a situation semantically matches, best-effort (you didn't know it was there, it found you). Cost: near-zero standing. (The memory index is a catalog that stays always-loaded; the entries get recalled.)
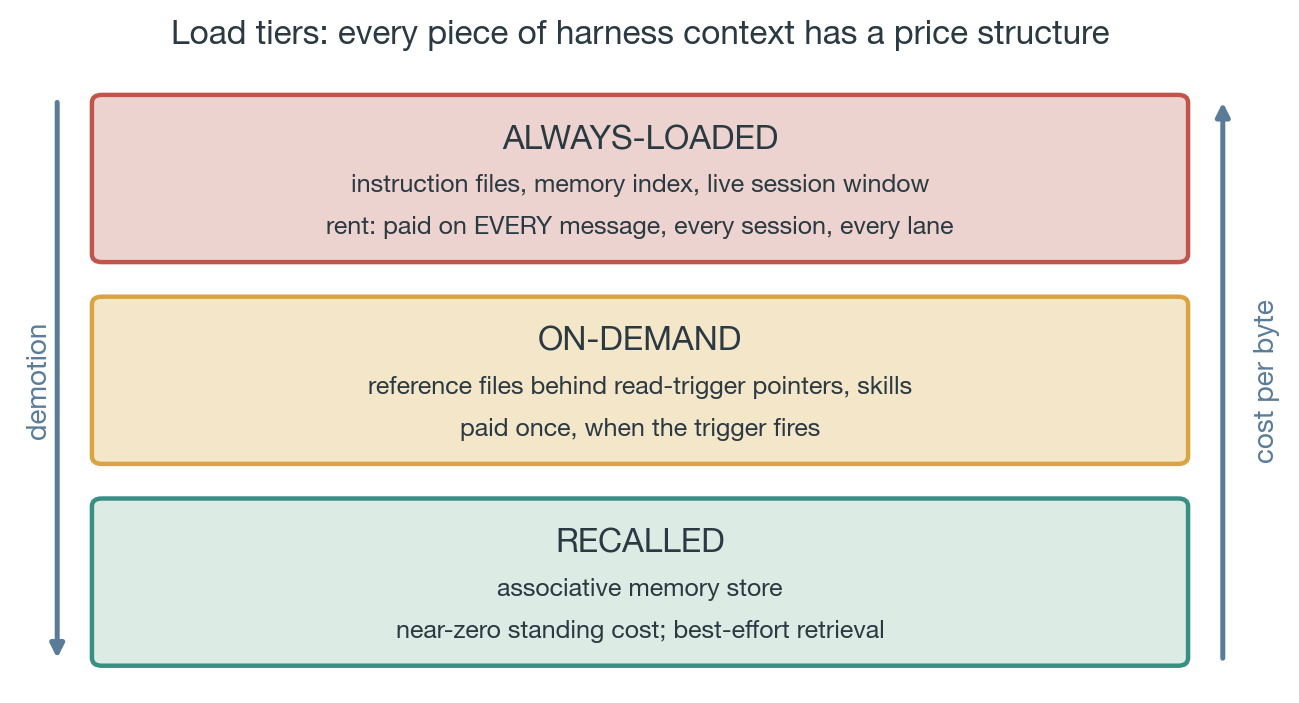
Figure 1: three load tiers, priciest on top; demotion moves content down.
Most bloat is a tier error: content sitting always-loaded that belongs a tier or two down. So for every paragraph, ask what earns the always-loaded tier? The instinct isn't new -- keep a line only if the model would err without it -- but we made it answerable by tier and cost. A piece earns the always-loaded tier only if it passes a four-question test. It must be:
A mal-firing-expensive rule. If forgetting it once costs more than its tokens cost forever (e.g. IP-hygiene, customer-trust discipline, one-way-door checks), it stays. This is insurance, overpriced until it fires.
A standing operating rule. How the work gets done by default: house style, a routing policy, a workflow convention. It fires on every relevant turn, so demoting it saves little and just lets the default rot.
Live sprint state. What the next session must know before writing any code, live being operative: state from a closed arc fails this test the moment the arc closes.
A pointer. One line saying where on-demand content lives and when to read it.
Everything else demotes.
That fourth one has a subtlety that took us an embarrassing while to learn: a bare file path never gets opened. "ops notes: see OPS.md" is write-only: no future session has a reason to follow it at the right moment. The pointer has to name its read trigger: read this before generating an invoice; read this if the CLI binary goes missing; read this before any client meeting. You're not storing a location, you're storing a conditional ("if situation X, load Y"), and that one line is the entire standing cost of content that used to fill pages. The mechanism that will load the content decides where it lives: procedure becomes a skill, invoked by name; reference context goes behind a trigger pointer; a lesson becomes a memory entry, recalled.
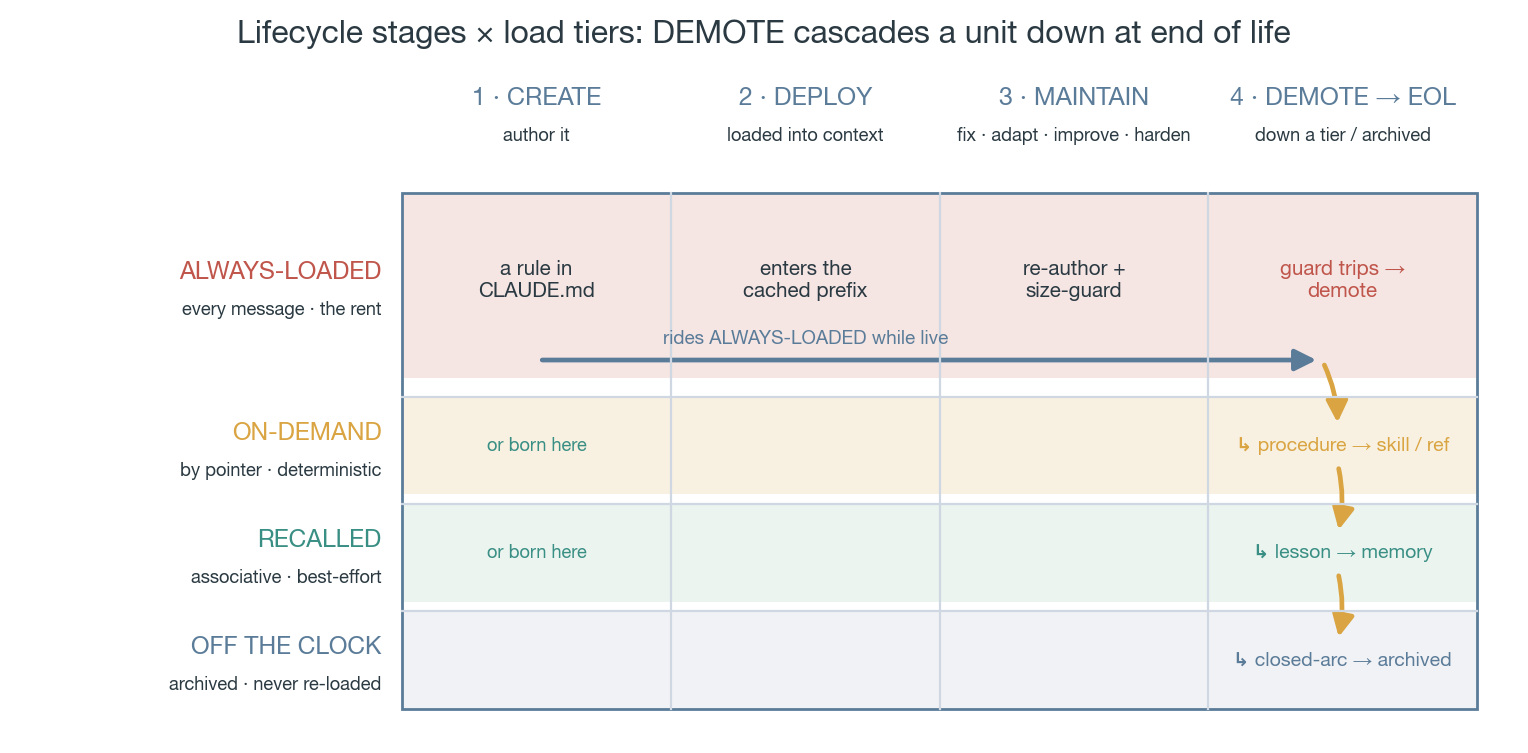
Figure 2: the lifecycle at a glance. A unit rides the always-loaded tier while live (CREATE → DEPLOY → MAINTAIN), then at end of life DEMOTE cascades it down to the cheapest tier that fits.
A harness is more than its files
The load tiers ask one thing: what a piece costs, and when. But a harness is more than passive text; its other parts sit on a second axis, not what it costs but what kind of thing it is:
Content the model reads: instruction files, reference docs, memory entries.
Capabilities invoked on demand: skills, MCP tools, subagents, slash commands.
Mechanisms that fire on their own: hooks -- the size guard that enforces this whole discipline is one.
Packaging that bundles the rest: plugins.
Every component has both a kind and a load-tier footprint, and it's the footprint HLM governs:
Instruction file (content): the file itself (the rent)
Reference file (content): one pointer line
Memory (content): the index (entries are recalled)
Skill (capability): its listing line; the body loads on invoke
MCP server (capability): tool names upfront; full schemas load on use
Subagent (capability): a fresh context: re-loads CLAUDE.md + tool/skill setup
Hook (mechanism): near-zero; injects only when it fires
Plugin (packaging): inherits its parts' footprints
Two are easy to miss, because the instruction file never shows them. 1. A connected MCP server (an external-tool plug-in, like Gmail or a database) keeps its tool names in the prefix and pulls each full schema in only when Claude first uses that tool, so integrations you've connected but never touch look free until they aren't. 2. And a subagent (a helper instance the main session spawns for a sub-task) starts from a blank slate, re-loading CLAUDE.md plus the tool and skill setup every time one is launched. The discipline is identical across all of them: one budget, the four-question test, the human gate, applied to the whole surface, not just the file.
The demotion ritual: archive first, then collapse
So we ran the pass. Closed sprint arcs collapsed from paragraphs to one-line pointers; the invoice table moved behind a trigger; stable strategy context moved behind "read before X" pointers. Result: 47.4k characters down to 32.5k on the project file, 7.7k to 4.1k on the global one, roughly 4.7k tokens saved per boot, in every lane, with zero information deleted.
That last clause is load-bearing. The ACE paper (Stanford/SambaNova, 2025) names two failure modes of letting an LLM curate its own context: brevity bias (iterative rewriting drifts toward vaguer summaries) and context collapse (one bad rewrite destroys accumulated detail no future iteration can recover). The ritual is built against exactly those: archive verbatim first, then collapse to a pointer. Every paragraph leaving the always-loaded tier lands byte-for-byte in an archive file before its slot becomes a one-liner. Demotion changes a tier; it never destroys information. Compression you can reverse is an optimization; compression you can't is a slow-motion deletion.
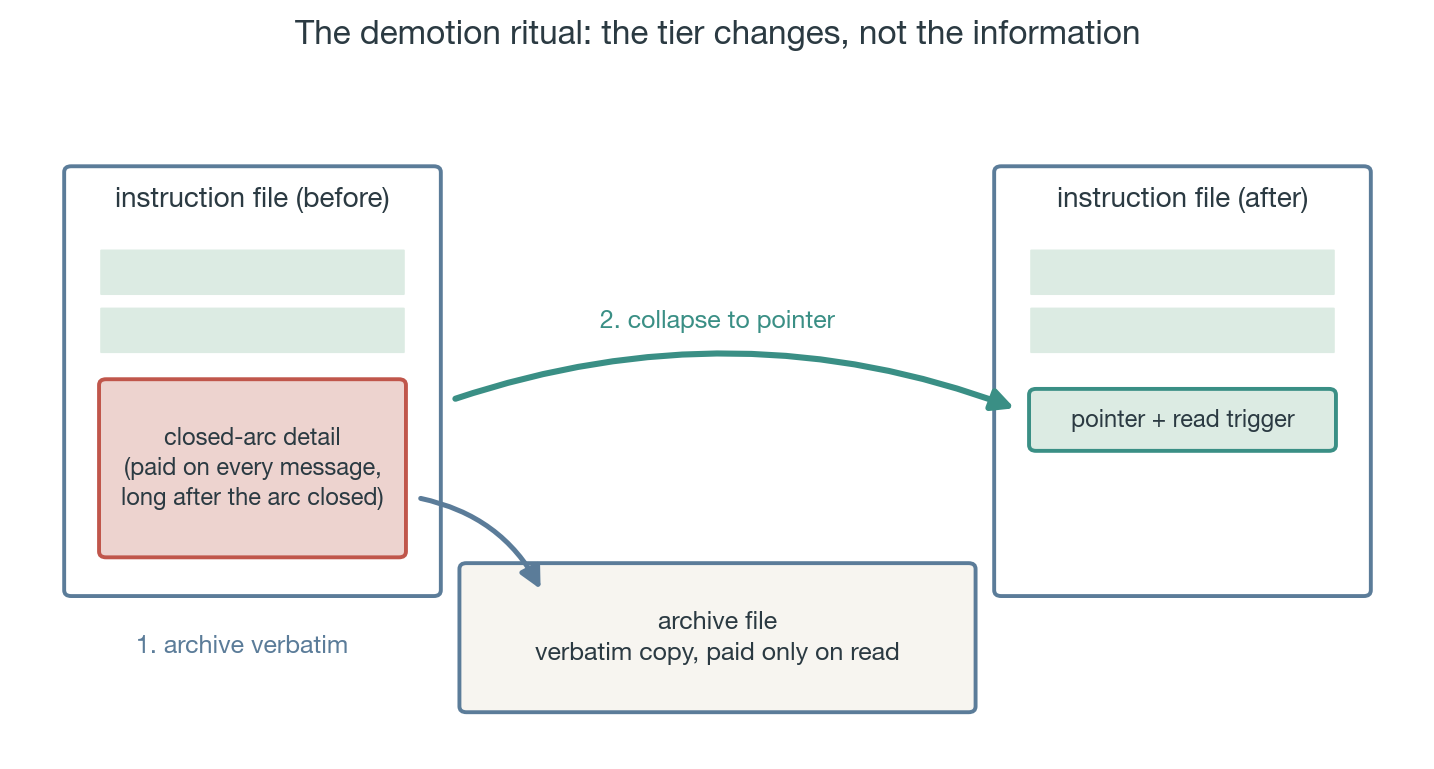
Figure 3: archive verbatim, then collapse to a pointer; always recoverable.
And demotion fires at lifecycle events, not ad hoc: an arc closes → its state collapses at wrap; a month completes → its row moves to history; a strategy stabilizes → it becomes a reference file. Tie the ritual to events that already happen and it runs without anyone remembering to.
The loop that keeps itself healthy
The fixes before this one didn't stick: the file regrew every time. What makes this HLM rather than spring cleaning is a standing loop that notices regrowth before it becomes pain.
The mechanism is deliberately simple: a session-start hook checks each always-loaded file's character count against green/yellow/red zones. Ours: global 6k/9k, project 35k/45k, memory index 25k/35k, calibrated to put the pre-trim 47k state solidly in the red. When everything is green the hook is silent: zero output, zero tokens, zero cost. It only spends words when it has something to say.
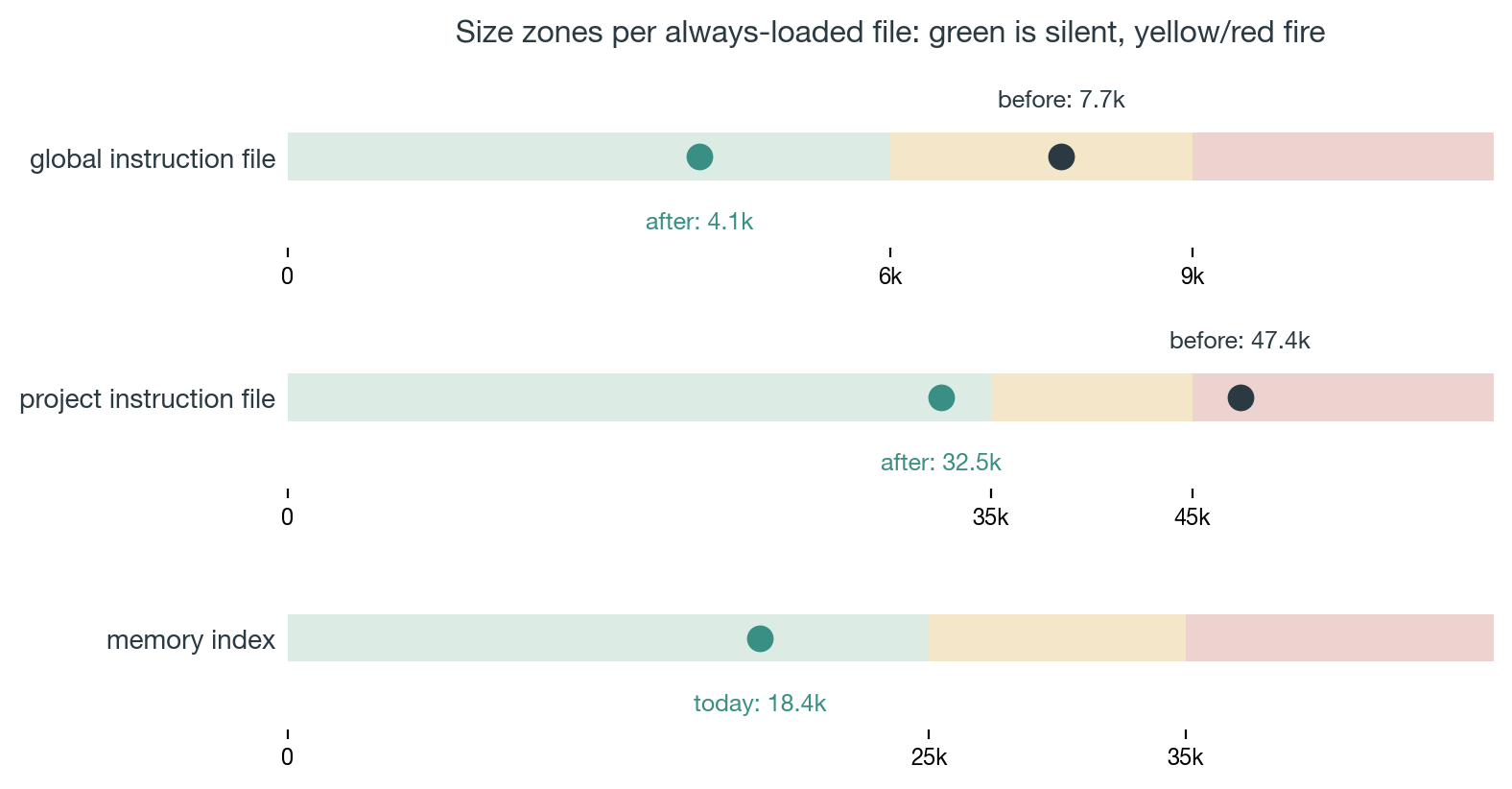
Figure 4: global and project files before (dark dot) vs after (green dot) the trim, against each file's green/yellow/red size zones; the memory index sits at its current 18.4k, comfortably green.
When a zone trips, the interesting part happens: the hook's output is injected into the model's context at session start, and it doesn't say "file too big." It carries the ritual: archive verbatim, collapse closed arcs to pointers, move stable context behind read triggers, surface the plan to the human before editing. A future session, months from now, run by a model instance with no memory of why any of this exists, gets handed the procedure exactly when it's needed.
In pseudocode the whole loop is unremarkable:
# session-start hook: runs before the model sees the first prompt
breach = [f"{f} is {zone(f)}" for f in always_loaded_files if size(f) >= f.yellow]
if breach:
inject(breach + DEMOTION_RITUAL) # model proposes the trim; human approves before any editAbout forty lines of bash in practice; I've packaged a generic drop-in version as a companion to this post. The full shape:
Deterministic detector → instruction injection → model proposes → human gates the one-way doors → new baseline.
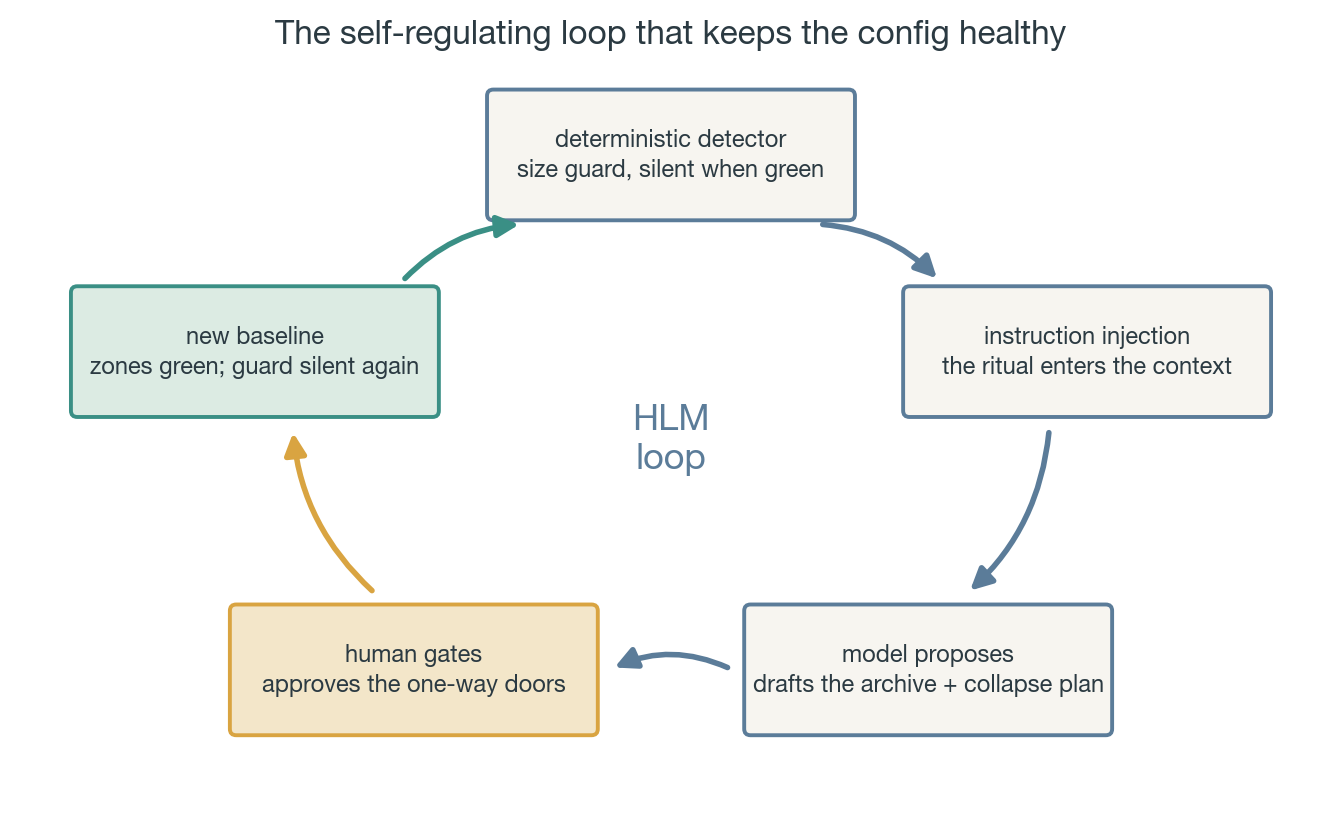
Figure 5: automated except the human gate on the one-way doors.
The rule that makes it safe deserves stating on its own: automate detection and proposal; gate the decision. The script is deterministic and cheap, so it runs every session without drift of its own. The model is good at drafting the tedious restructuring, so it does. Human gates the cut, as deciding what the system no longer needs to know by default is a one-way door and a judgment call with a blast radius.
The hottest tier is the one you're sitting in
Everything so far has been about files. But if HLM is a discipline and not a one-file trick, it has to hold on a surface that isn't a file at all, and the most expensive always-loaded surface is exactly that: the conversation window, the session's accumulated history re-carried into every turn. The instruction files are a fixed charge; the window is rent that grows as you work. It has its own lifecycle, months compressed into hours: boot → build state → wrap → demote, where wrap banks the durable parts into the repo and memory store and lets the rest evaporate.
Which forces the question every long session reaches: continue, or restart fresh? The immediate answer is sunk-cost-shaped (the context is already paid for, keep using it), and like all sunk cost it votes for neither option, because the spend is gone either way. The decision variable is forward cost, and it splits cleanly:
Continuing re-carries the whole history into every future turn: cheap at cache-read prices while the cache is warm, a full re-write once it goes cold (the cache expires after a stretch of inactivity), plus a quality tax (per the context-rot work, padded history degrades every answer).
Restarting means paying a boot and rebuilding state.
So the rule falls out of the same logic as the file-level test:
Continue when the window holds unique, task-relevant state. Restart when it holds history the next task doesn't need.
The restart penalty is the whole question, and it varies enormously: near zero when the task's state lives in the repo, prohibitive when it lives only in the window.

Figure 6: forward cost vs restart penalty decides, not sunk cost.
The day of the audit handed us both, hours apart. An engineering session mid-design-amendment got continue: its window held reasoning state, the why behind the design, banked nowhere in full; rebuilding it would have cost far more than the carry. An admin session pivoting from invoices to engineering got restart: its window held nothing the new task needed, the state already lived in the repo, so the penalty was zero. It's the four-question test at window granularity: a window with no unique, task-relevant state is just a closed arc that hasn't been demoted yet.
One catch: the window is the only surface here with no automatic tripwire. Its signals are opt-in (a context meter in your status line, a /context readout when you stop to ask), and none taps you on the shoulder before the cost lands. So the discipline isn't a tripwire, it's a habit: restart at task boundaries, the same moment you wrap and bank live state. The gauge reports; the habit acts.

Where this sits
Load-tier demotion is one practice; the session window is a second. Two surfaces don't make a rule, but they rhyme. Each is paid standing, each drifts, each has edits you'd want gated, and the same handful of moves generalize to the harness's other standing surfaces → memory indices, skill listings, permissions:
Budgets. Every always-loaded surface gets a size zone, the way every service gets a latency budget. Unbudgeted surfaces grow; that's an observation, not a prediction.
Tripwires. Deterministic, session-start, silent-when-green. A guard that costs tokens when healthy gets deleted; one that fires only on breach survives.
Drift detection. The config you think the harness runs and the one it actually runs diverge as hooks change, skills accumulate, and permissions widen. Snapshot the live state, diff it against what you believe you're running, surface the gap (a desired-vs-actual diff): a Terraform plan pointed at the model-facing surface.
Archival (verbatim-first) and the human gate carry over unchanged, and they scale up a second axis: a shared team file adds writers and cross-developer drift no individual sees, and earns proportionally heavier discipline.
The frontier is mostly heading the other way, toward more autonomy.² HLM draws a different conclusion from the same evidence: where ACE answers context-collapse with better automation, we answer with a human, but only at the one-way doors, the irreversible edits where one IP-protection rule summarized into ambiguity can cost a client relationship. Karpathy's LLM-wiki (April 2026) is the same idea one tier down — an agent-maintained, cross-referenced markdown knowledge base — but without a cost model, a demotion path, or a required human gate. The supporting machinery already exists, scattered across LLMOps and infrastructure tooling,³ but I haven't seen it pulled together for the harness's standing, always-resident config: costed by load tier, gated by mal-firing cost, not an output-quality eval. (Our own trimmed file still runs well over the "keep it under 150 lines" advice, deliberately: the four-question test sets the floor, not a line count.)
Every one of those optimizers works against a metric, but the rules most worth protecting are the ones no metric reaches in time: no eval catches an IP-protection rule summarized into ambiguity before it leaks (and per Chroma's context-rot study, a bloated file is a quality problem too, not just a billing one). So the genuinely new piece is the frame plus a gate criterion evals can't supply, wired into a system that holds itself to budget, which is, candidly, why this essay exists: dogfooding the discipline is the only honest way to advocate it.
Close the loop
One audit, one slice I could actually govern: instruction files that had bloated unnoticed, re-paid on every message across three parallel lanes. One demotion pass cut ~4.7k tokens per boot per lane with nothing deleted, and a forty-line deterministic hook now watches the zones, injects the ritual when one trips, and hands the decision to a human.
No single piece is clever; the discipline is that they form a loop that holds itself to budget without us. All of it is lifecycle management: the boring practice software has applied to every other artifact it depends on, finally pointed at the harness.
Your instruction file is an engineered artifact. It has a cost, a drift mode, and a lifecycle. Govern it like one.
Notes
The cache write runs about 1.25× the normal input rate; each re-read, roughly a tenth of base. A fan-out to subagents re-loads the standing files in each subagent's own context.
MemGPT pages context like an OS memory hierarchy; ACE treats context as a self-evolving playbook; DSPy optimizes prompts against a metric; Anthropic's context-engineering guidance covers the runtime side.
Prompt registries (LangSmith, Langfuse, PromptLayer) version task-time prompts; infrastructure-as-code has drift detection and policy-as-code; rule-based guardrails (NeMo, Constitutional-AI-style) enforce standing rules. The closest prior map, Context Engineering 2.0, lays out a "context lifecycle" but only descriptively, with no cost or budget on the bytes you re-pay every message.

Comments